AI Research Engineer @ Leonardo Labs
AI Research Engineer with a Master’s degree in Computer Engineering, specializing in Natural Language Processing (NLP) applications.
Extensive experience in developing software and AI models, with a primary focus on the NLP field.
Professional interests encompass Natural Language Processing, Reinforcement Learning, and Software Engineering.
Socials
Experience
AI Research Engineer
- Engaged in research and software engineering activities for both internal and European projects.
- Engineered software systems using NLP models for automated information extraction from documents.
- Applied large language models (LLMs) across multiple applications (e.g. question answering, clustering, text generation, triplet extraction, …).
- Worked on image super-resolution employing Generative Adversarial Networks (GANs).
Junior Data Scientist
Education
University of Rome, Tor Vergata
Thesis: A new agent-based NAS (Neural Architecture Search).
Final mark: 110/110 cum laude
University of Rome, Tor Vergata
Skills
- Natural Language Processing
- Reinforcement Learning
- Deep Learning
- Machine Learning
- PyTorch
- HuggingFace Libraries (transformers, datasets, peft)
- LangChain
- Semantic Kernel
- Pandas
- Numpy
- Asyncio & Multiprocessing
- Python
- git
- linux
- bash
- MySQL
- MongoDB
- Neo4j
- Redis
- Docker
- Microservices Architecture
- RESTful APIs Architecture
Workshop - An adaptable method for developing an Open-domain Question Answering system
Conference - Multilingual Text Classification from Twitter during Emergencies
Natural Language Processing Tasks

The repository contains a series of natural language processing (NLP) tasks addressed using various methods and models. The tasks include text classification, named entity recognition, question answering, summarization, and text generation.
Web Data Extraction
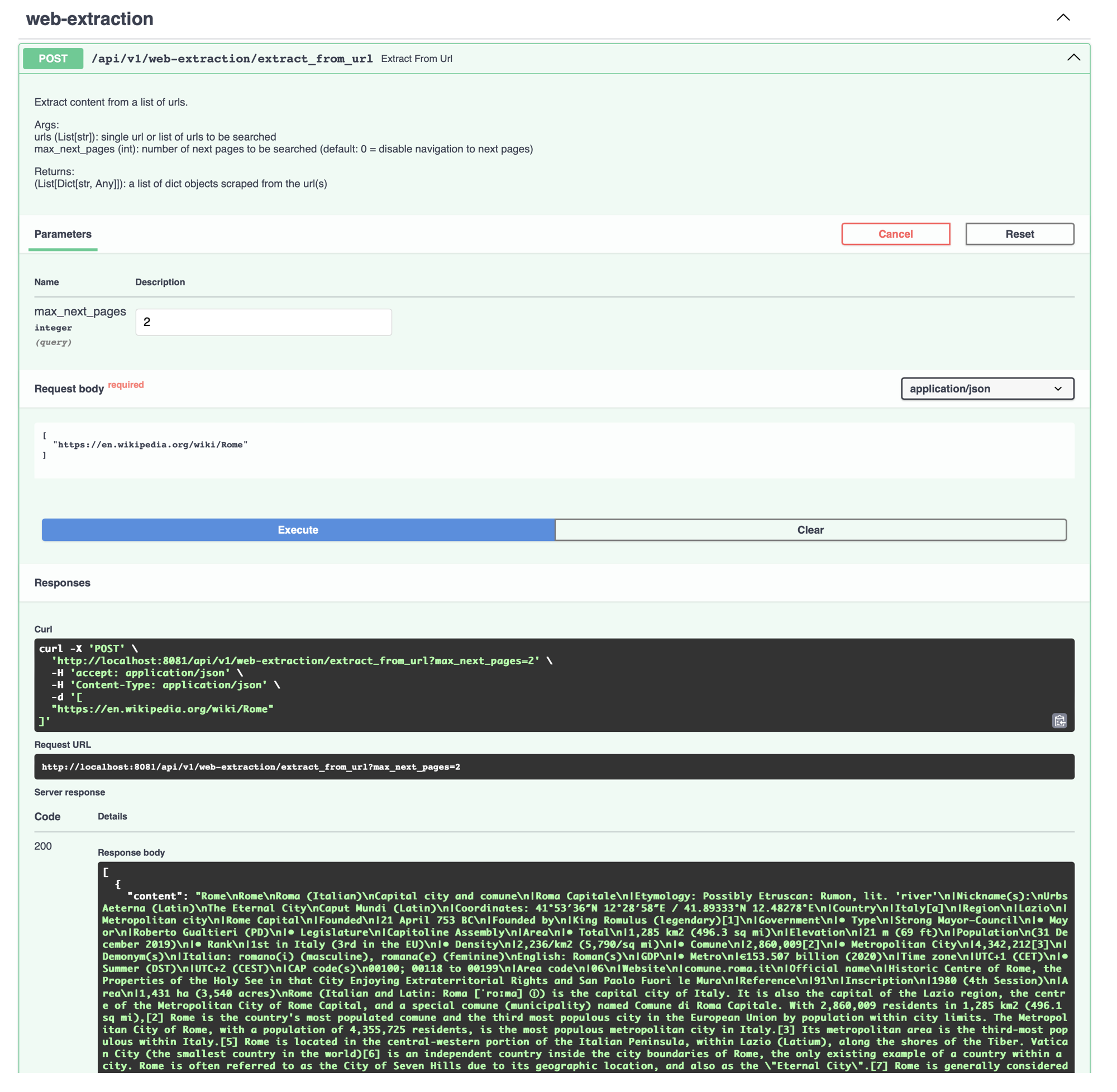
A simple web crawler and scraper has been developed to extract data from websites. The crawler operates on Scrapy, while the scraper utilizes BeautifulSoup. At present, the scraper is configured to extract structured data specifically from the Trustpilot.com website. For other sites, the scraper is designed to return unstructured text data